
This is Part II of our series of posts on retrofitting null safety onto existing programming languages.
In Part I of this series, we introduced NullAway, a pluggable type system for nullability for Java, which can prevent NullPointerException (NPE) crashes in first party code by explicitly annotating program locations that can contain null values as @Nullable and requiring checking for null before dereferencing such locations. We briefly mentioned that, for large existing Java codebases, adding these annotations manually can be tedious and time-consuming work.
In this follow up, we will talk a bit more about how the issues with manual annotation led to building NullAwayAnnotator, a tool we developed in collaboration with researchers at UC Riverside to automate the painful initial step of onboarding a large existing Java codebase into NullAway.
Some key takeaways:
Pluggable type systems like the one used by NullAway (or the JSpecify Nullness Specification in general) require pervasive annotations in your code to properly capture type information
This is simple for new code (same as adding regular static types), but introduces friction when migrating an unannotated codebase.
A large portion of the work of annotating an existing codebase can be automated. For a given pluggable type system, this automation is non-trivial to implement, but saves significant manual effort once available.
For NullAway specifically, we built an OSS tool for automated annotation of existing codebases, used it at scale at Uber, and described it in detail in a research paper.
Typing out your types
Let’s recap the story so far:
Pluggable types for Java extend the Java type system to refine which values are allowed at a particular location within a program.
Specifically, for every reference type
Tin the default Java type system, a nullability type system introduces both@Nullable T(the type representing either a valid reference to an actual object of typeTornull) and@NonNull T(the type accepting only valid references to objects of typeTexcluding thenullreference).Tools like NullAway can be incorporated into your build to check that a Java program conforms to this extended type system.
At first glance this would seem to imply that every occurrence of a type in a Java program would need to be augmented with either a @Nullable or a @NonNull annotation to produce a program that is checkable by NullAway. In practice, the situation is not nearly as dire. There are a number of cases where annotations can be elided:
Primitive types like
intorbooleanare not references and can never containnullas a value in standard Java, so they don’t require annotations, ever. They are implicitly always@NonNull.NullAway performs intraprocedural dataflow-based type inference, which means local variables don’t need to be annotated as
@Nullableor@NonNullas the tool infers their type annotation automatically (we also support inferring the nullability of arguments to lambda functions!).We use opinionated defaults to further reduce the annotation burden. In particular, for first party code, NullAway assumes that any occurrence of the type
Tin a method signature or field declaration means@NonNull Tunless otherwise annotated with@Nullable1.(Also, NullAway incorporates some handling of specific instances of inter-procedural nullability tracking, through
@Contractannotations, Java streams handling, etc. We ignore these edge cases in the rest of this introductory blog post).
The above leaves to the developer the task to manually annotate the type of any method argument, return value, or field that can take a null reference. From the original NullAway paper (see Table 1), this ends up adding up to 11-14 annotations per thousand lines of code.
For developers that are familiar with NullAway, working on already annotated codebases, providing these annotations as they add new code or change existing functionality is not noticeably harder than providing the static types Java already requires of them. Besides helping NullAway type check the code, these annotations serve as documentation to the developer about which locations in their program may or may not contain missing data in the form of null references.
However, the first time any codebase is onboarded into NullAway, developers need to provide valid annotations for all their existing code. This process is time consuming, tedious, and, unfortunately, non-trivial.
A simple example
To get a feeling for the process of annotating Java code for nullability, let’s consider the following illustrative - though highly artificial - example, lacking any kind of Nullability annotations:
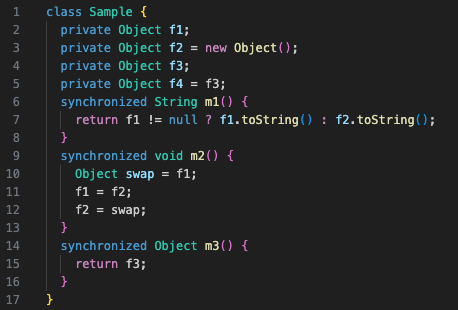
If we try to compile it as is, using NullAway as part of our build, we will immediately get two errors, one for each of the fields f1 and f3. These fields are both implicitly typed @NonNull Object, but are null after object construction, since null is the default value of any reference type andSample doesn’t have a constructor setting these fields to a non-null value.
Adding the corresponding @Nullable annotations, we get:
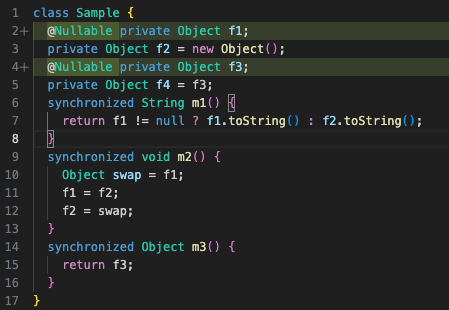
Trying to compile this updated code produces three new errors:
One on the declaration of
f4, which is assigned the@Nullablevaluef3One on
m3, since it now returns@Nullable(fromf3) without the method being typed as such.One on
f2 = swap;, sinceswapis inferred@Nullabledue toObject swap = f1;andf1being@Nullable, yet it’s assigned to non-null fieldf2(note that no annotation is required on the local variableswapitself due to our aforementioned intraprocedural inference).
So, we must again go to the code and add three new annotations:
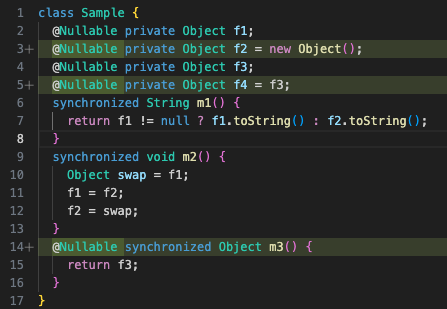
Unfortunately for us, this code still gives one more NullAway error: a dereference of null in the body of m1 :

Because f2 is considered @Nullable, and not checked for null before f2.toString() (unlike f1 in that same line), NullAway will complain that this is a potential dereference of null.
In reality, this is a false positive. Due to the fact that: (a) field f2 is initialized to a non-null object, (b) the logic in m2() always swaps the values of f2 and f1, and (c) there are no other ways to set the values of these fields or access them concurrently with a call to m2(), we actually have the following high-level invariant for any objects o of type Sample:
At entry to any method o.m{i}(), o.f2 == nullif and only ifo.f1 != null”
Because m1() first checks if f1 is null, and only dereferences f2 if it is, then both dereferences are actually safe, and no NPE is possible.
Our nullability type system is not currently able to capture this kind of invariant directly. While we could extend NullAway to allow developers to express that particular relation between f1 and f2, there will always be cases we don’t handle. In fact, this is a general property of any non-trivial static type system (including Java’s default one): for any such type system, there exist valid programs in terms of the absence of runtime type-errors that will be rejected by the type checker2.
While the above example is certainly contrived, real code designed without nullability in mind will occasionally run into such false positives. In practice, a common solution is to add a redundant check, a runtime assertion (i.e., through Objects.requireNonNull(...)), or to refactor the code in such a way that it has identical effect but can be type checked.
So, we could end up with, for example:
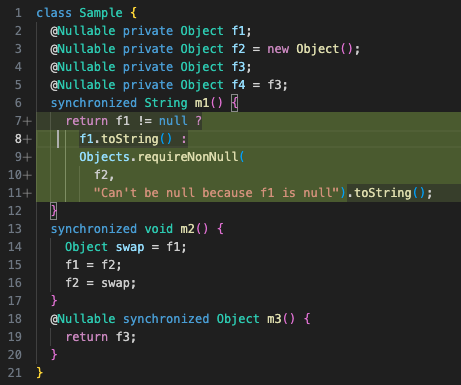
After six errors and three build iterations, we have successfully annotated ~20 lines of code.
The small snippet of code above is designed to show a large number of NullAway errors/annotations required, so we wouldn’t actually expect this many iterations to annotate “natural” code of similar length (recall that we need 11-14 annotations per KLoC on average). However, when enrolling any previously unannotated codebase into NullAway without specialized tooling, the above process must be repeated across all files in the project. Where ‘the project’ might be the entire repository, a particular build target within a large monorepo, or any subset of the code we wish to check with NullAway.
And, as most things, this is further complicated with the introduction of some real world development considerations…
Charging Windmills
As mentioned in Part I, NullAway was originally developed at Uber to internally replace Meta’s Eradicate, which was used from very early on to check nullability typing of Uber’s Android codebase. This means that, modulo some small differences between the two tools, Android code was already annotated in a way that was mostly compatible with NullAway.
However, as Uber began consolidating its server-side Java code into a single Java monorepo, it was natural to consider enrolling said monorepo into NullAway to reduce server-side crashes. This was easier said than done, as this server-side codebase was much larger, more diverse (having been until recently developed as independent microrepos with sometimes disparate tooling), and never built with nullability typing in mind.
Annotating the entire codebase from day one as it was migrated into monorepo quickly proved infeasible. Instead, code was separated into annotated and unannotated code at the unit of a specific build target. Annotated code built with NullAway as part of the local (and CI) build, producing errors as per the standard rules for the tool. Newly created build targets would be deemed annotated by default, as would those whose developers wished to manually onboard into NullAway for extra safety. Then, our team set itself to the task of slowly, one by one, centrally enrolling these existing unannotated code targets into NullAway.
This proved easier said than done for a number of reasons:
First, as we saw in our example above, the process of figuring out the right annotations for code is often an iterative fixing process, in which one field, method argument, or return must be marked as @Nullable due to null value being assigned to it, which then causes other locations down the line to become @Nullable themselves. Performing this manually for a large existing codebase often involves a tedious process of adding an annotation, rebuilding the target, examining the compiler output for any new NullAway errors, and fixing those in turn.
Second, there might not exist any valid assignment of nullability annotations for the given code. Not only is it possible for genuine NPE crashes to be present in the codebase (requiring real fixes that might need a deep understanding of the code’s business logic), but - as we also already noted - there will be valid code that fails to type check. In fact, the existence of this code can cause us to backtrack in our manual annotation process, as we realize that a different fix or refactoring is needed rather than blindly annotating a result as @Nullable.
For an example of the later issue, consider the following variation on the code of Sample:
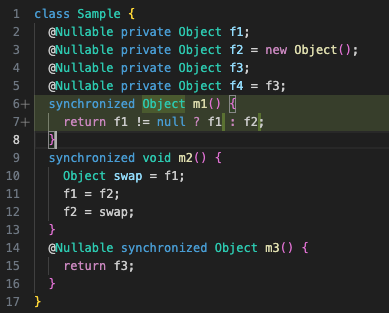
Here, because of the invariant we described previously, either f1 or f2 is guaranteed to be non-null on entry to m1(), and it is this non-null field that will serve as m1()’s return value (unlike the original code, where said field would get dereferenced instead). Because NullAway doesn’t understand this invariant, it will report an error saying that @Nullable value f2 can be returned as the (implicitly) @NonNull return of method m1(). We could “solve” this reported error by marking the return value of m1() as @Nullable, but this would just lead to errors down the line when this value is correctly used as being non-null. Instead, we must realize that the full program logic implies f2 can’t be null at that point, then either restructure the code or add a runtime check like we did in the last section.
Third, because we were modifying other people and other team’s code, our manual changes, quite reasonably, required review by the respective owners of the changed target. Code reviews take time and might not be prioritized immediately by owners. At the same time, other changes are constantly being made to the codebase. Since annotation changes are pervasive (they touch most files in a target), getting merge conflicts while rebasing over other PRs was common, as was the need to annotate the newly introduced feature code as well, triggering a re-review.
Fourth, the above was further compounded by the fact that adding a @Nullable annotation to the declaration of a method or field in one target T1 could trigger new errors in other targets which depend on T1 and which were previously enrolled in NullAway. This led to more cascading annotation changes across targets and more reviews by multiple teams being required, which only added to our rebasing woes above.
In the end, it quickly became clear that we needed a better approach than manual annotation.
Automating annotating
Naturally, the next step upon discovering a repetitive and painful manual process is to automate. While at Uber, we worked with researchers at UC Riverside3 to solve this problem by producing the NullAwayAnnotator tool.
Looking at the manual annotation process from a bird’s eye view, we see that we are running NullAway, adding annotations to resolve the immediate errors the tool spits out, and then starting the process all over again, until we end up with code that builds with NullAway or errors that cannot be resolved by adding new annotations. This task can be automated.
In practice, however, such automation is non-trivial. Even for a single small target, adding annotations this way without backtracking can often increase the number of errors reported in the end (sometimes by nearly 3x in our experiments, see Table 1 of the paper), and produces many spurious @Nullable annotations in code that wasn’t built to pass NullAway from day one. The goal, for code that isn’t known to be fully type-checkable, is to produce annotations that minimize the number of remaining errors, and thus the portion of the code that is unsafe or must be changed by hand to conform to the type system.
Thus, the tool introduced backtracking to explore the search space of possible annotations, looking to minimize the number of remaining NullAway errors. It would keep track of which @Nullable annotation was added in response to which error, and vice versa when an error was introduced after adding a new annotation. This way, it can explore chains of fixes up to a particular depth, and keep them only if applying the full chain actually reduces the number of total errors reported by NullAway.
Exploring a chain of fixes is needed, since sometimes, adding an annotation may temporarily increase the number of errors, but those errors can then easily be solved as a follow up. From our Sample class above, consider the addition of @Nullable to f3, which turns a single error into two new ones, but where each of the introduced errors can then be fixed with a single additional annotation. That is, with a depth-2 chain of fixes. Empirically, a chain depth of 5 was found to be enough to find good sets of annotations with higher depths achieving little improvement over it at significant performance cost.
Once the tool has worked to minimize the number of remaining errors in a given build target or codebase, it adds suppressions for those remaining errors, leaving them as candidates for future manual fixing. The advantage of suppressing in this way is that the change then contains only @Nullable annotations and said tooling suppressions, neither of which affect program runtime behavior. Because of this, a PR containing this change can be created and landed automatically, without human review.
Obviously, such behavior-preserving changes will not solve existing crashes due to null dereferences in the original code, since that would be by definition changing runtime behavior. However, by checking most code with NullAway and adding suppressions only to those methods/classes we fail to annotate correctly, the tool highlights the areas that could contain NPEs. Additionally, since newly introduced code outside of those suppressed regions is now checked by NullAway, developers can gain confidence that no new NPEs are being introduced by subsequent changes (a confidence which increases as suppressions are resolved and removed!).
One thing to note is that the above backtracking algorithm requires running NullAway to confirm the number of errors introduced by each “fix”, and running NullAway requires rebuilding the project, this process can be very slow, even with automation (and build caching). In our experiments, projects as “small” as a few tens of thousands of lines of code would require thousands of builds and longer than 8 hours to run the naive search as described above. One of the main technical contributions of the full NullAwayAnnotator tool is a graph-coloring algorithm over the program structure that can test multiple annotations added in different locations simultaneously and distinguish which annotation led to which set of errors.
Another important feature is awareness of different build target boundaries and analysis of downstream build dependencies. The tool can optionally be configured not to add any annotations that would cause errors in downstream dependencies already enrolled in NullAway, at the cost of leaving more errors suppressed in the specific target being currently annotated. This feature was instrumental at Uber in allowing us to annotate and onboard one target at a time.
Overall, prior to publication of our paper, this tool was used at Uber to annotate over 160 production targets, totaling over 1.3 million lines of code, with only an average of 6.32% of the code for any given target left unchecked due to any kind of suppression. Anecdotally, many more targets have been enrolled internally this way since then.
The in-depth details of the tool’s inner workings, optimizations, and tradeoffs are explored in our FSE 2023 paper, along with more details on the numbers mentioned above. The tool itself is available as open-source at https://github.com/ucr-riple/NullAwayAnnotator
What’s Next?
One interesting question that might come to mind based on all this discussion about the challenges of annotations and how to add them automatically is whether or not annotations are necessary at all to provide null safety. In the next post in this series, I hope to talk about NilAway, our NullAway-equivalent for Go. Go, unlike Java, doesn’t natively have annotations as part of the language. Is there any way we can infer nilness typing for Go then, without requiring manual annotations? The answer is yes! (But there are some trade-offs)
If you are a Java dev, don’t fret; besides NilAway, there are a number of topics on NullAway itself we have left to explore, even after two long-ish posts on the subject. Eventually, I hope to write about:
How we deal with third-party Java libraries and other unannotated code called from NullAway enrolled code.
How we handle streams, IDLs, API nullability contracts, etc.
Examples of pluggable type systems beyond nullness. How about a type system for safe access to the Android UI thread?
We invite you to join our Slack community, where we continue to explore and discuss these topics further.
1. There are actually multiple ways to change this default, such as using the JSpecify spec’s @NullUnmarked annotation, or various configuration flags for NullAway itself. However, for the sake of simplicity, this blog post assumes we are working with code where an unmarked T means @NonNull T.
2. In general, this is true because of Rice’s Theorem, and a simple proof for arbitrary type systems by reducibility to the Halting Problem can be found in John C. Mitchell, Concepts in Programming Languages, pg 134 (“Conservativity of Compile-Time Checking”). Less general but more annoying in practice examples exist for any practically useful static type system.
3. Primarily Nima Karimipour (Ph.D. student at UCR, and Summer intern at Uber), as well as his advisor and NullAway’s original author Manu Sridharan.
