
We’re thrilled to announce that our paper on lightweight methods for polyglot code transformation has been accepted at PLDI 2024! In this post we’ll walk through the main conceptual insights of the research, and how it will contribute to building better tools for automated code maintenance.
In today’s software industry, code bases are increasingly large-scale and polyglot, which we’ve explored in a previous blog post. The larger and more complex code bases become, the more important it is to be able to automatically clean up code, so as to manage technical debt and enhance maintainability. Moreover, as code bases increase in size and complexity, it becomes harder to effectively apply most existing automated code refactoring tools.
Automated code refactoring tools typically fall into two buckets: lightweight syntactic tools (which are easy to use but limited in expressivity) and powerful imperative frameworks (which aren’t language agnostic). PolyglotPiranha is a new abstraction we’ve designed to carefully extend the expressive power of lightweight syntactic refactoring tools while retaining their ease-of-use and polyglot nature. To understand how we got there, let’s dive deeper into the limitations of existing tools.
Lightweight Syntactic Tools
Lightweight syntactic tools (such as ast-grep, Comby, etc.) are great because of their simplicity: they can be fast, and allow you to easily write syntactic matching queries. But they fall flat when you need to perform a code refactoring that cascades multiple changes, which happens very often (dead code cleanup, vulnerability mitigation, some library migrations, etc.). Suppose you want to delete a function which is annotated with @Value(“location”), and rewrite all code to use true in its place:

You could first use Comby, ast-grep, or even vanilla grep to search for the annotation pattern. But then you would have to manually remember the corresponding method name (isLocEnabled), and then kick off a second code search using that name.
In that second code search you would then replace isLocEnabled() with true, but just doing that would leave a bunch of code smells, such as a left-over true || x > 0 which should be cleaned up. You could then try manually invoking many additional cleanup patterns, but existing tools would search those across the entire codebase or file, leading to poor performance and additional code rewrites that you didn’t intend.
In fact, this automated refactoring involves 6 distinct and interdependent refactoring steps:
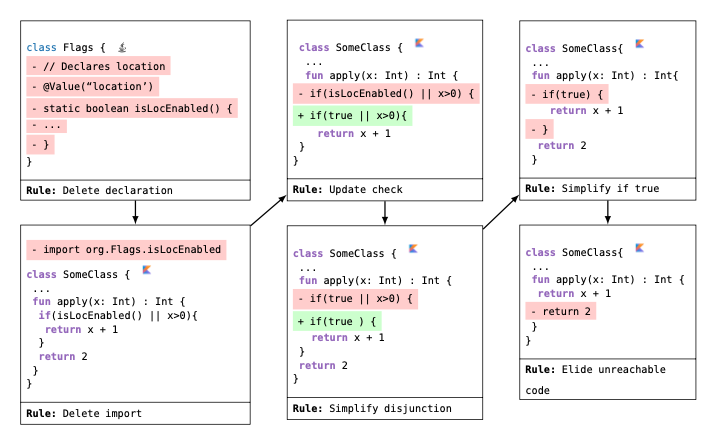
Tools like Comby and ast-grep have no means to help with chaining together multiple steps at once. In essence, lightweight syntactic methods are fantastic at the limited task of matching and rewriting, but automated refactoring requires higher-level abstractions.
Imperative Transformation Frameworks
On the other hand, there are extremely powerful frameworks for writing complex code transformations, such as OpenRewrite and jscodeshift. With these tools you can achieve practically any code transformation imaginable, but their complexity has several downsides. First, they typically don’t provide a declarative DSL that enables non-experts to intuitively write rules, like in ast-grep. Instead, you write transformations algorithmically, requiring you to have deep knowledge of the tool and the nitty-gritty details of the target language and its compiler internals. Second, they often require deep integration in the build systems of the target language, making cross-language transformations challenging and impacting scalability.
Big Idea: Propagating Context Between Lightweight Syntactic Rules
We love the declarative simplicity and polyglot nature of lightweight syntactic methods for rewriting source code, so our ideal solution would be to see if we can extend these DSLs in such a way that allows us to express cascading rewrites.
To see if we can do that, let’s walk through the example above and build refactoring rules one step at a time. The first step of globally searching for the annotation @Value(“location”) and deleting the method is the correct place to start, and we can do that with a Comby rule:

Here we have capture groups: trgt (which will be location) and name (which will match isLocEnabled). Since we now know the name of the method to delete (in the name capture group), we should do a global code search for all places that import and call name. Thus, the key insight here is that we want to be able to propagate captured matches between rules, and thus pass contextual information along.
Supposing we have replaced all call sites with true, we’ve now successfully removed the method and all references, but left a terrible mess in the code! Specifically, there’s unsimplified expressions and conditionals, like true || x > 0. Ideally, we should be able to apply a large set of standardized code cleanup rules to simplify this, but we need to surgically apply these cleanups only to the parts of the code where we just performed a rewrite, so that we don’t introduce any irrelevant code changes elsewhere. To do that, we need to be able to run a refactoring rule only within some scope defined by a previous rule. In a sense, this is another type of context (scoping context) which we need to pass between refactoring rules.
PolyglotPiranha is a new abstraction for combining multiple lightweight syntactic rules based around the idea of propagating contextual information, and thereby use capture groups and scoping to apply rewriting rules exactly where they are needed, either globally, or locally within a class, method, AST expression, etc.
Graphs of Transformation Rules
The core structure of a PolyglotPiranha automated refactoring routine is a graph, consisting of lightweight syntactic rewriting rules as nodes, and directed edges between the nodes, with at least one node marked as a root node. The graph structure encodes the cascading relationships of the individual rewriting rules: if there is an edge from rule A to rule B, and rule A matches (and possibly rewrites the code), then rule B will attempt to match while being passed any capture groups from rule A. Additionally, the edges are labeled with a modifier specifying the scope (relative to rule A) where rule B should try matching. This graph structure allows us to cascade refactoring steps in a controlled manner, and propagating captures along these edges enables interdependent rewrites.
Using this abstraction we can fully implement the refactoring task of deleting a method and replacing all calls to it with true, using this graph of rewrite rules. We start with the Delete Declaration rule discussed above, then perform a global search and replace for all uses of the method, and follow it with 3 additional cleanup rules, scoped to the local AST expressions:
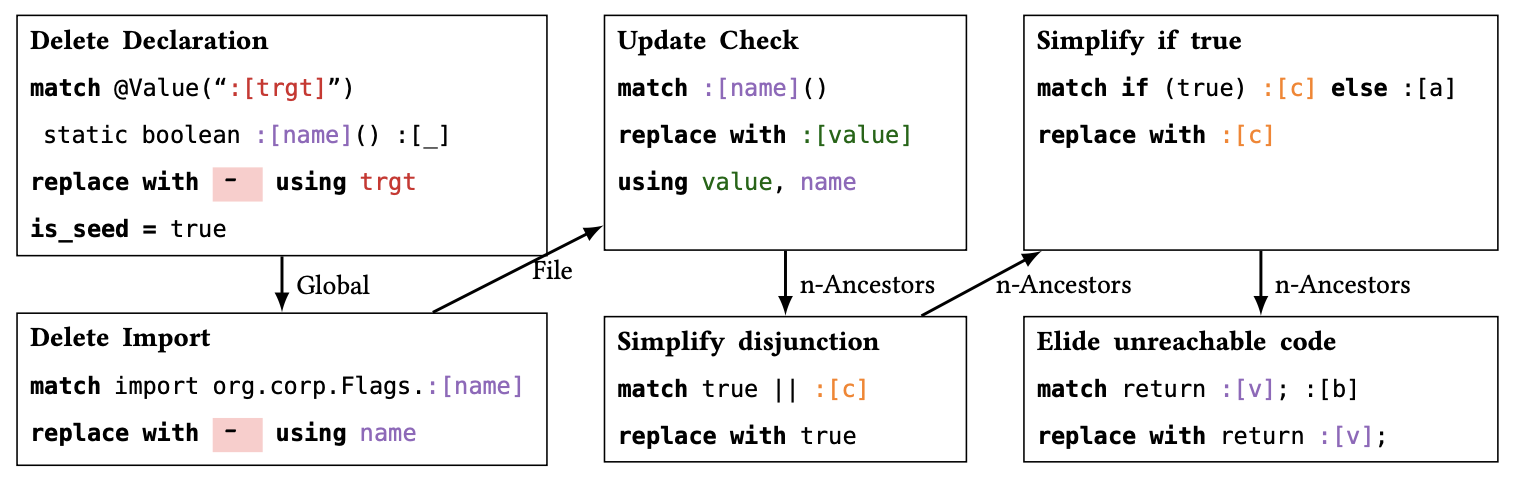
One really cool thing about this design is that the graph structure is agnostic to the matching syntax that is used within each node. Here, we’ve used Comby rules to implement each individual node, but other matching tools can be used, including tree-sitter queries, concrete syntax and regular expressions.
At Gitar, we strongly believe that these new abstractions (and others!) we’re developing can pave the way for a future of seamless automated code maintenance, and vastly increase developer productivity. In this post we’ve walked through the core insight behind PolyglotPiranha and how it can be applied to solve practical, large-scale refactoring problems. Next week, we’ll take a dive into the internals of the runtime engine of PolyglotPiranha, and survey how well it performs on industrial-scale code bases!
